前回 SteamDeck には簡単に Linux 環境をインストールできることがわかりました。SteamOS には最初から distrobox コマンドがインストールされており、コマンド一つで各種 Linux 環境を入れることができます。
例えば Ubuntu をインストールするならコマンドラインから「distrobox create -i ubuntu:22.04」のように実行するだけです。apt 経由で各種ソフトウエアを利用できるので開発環境の構築なども簡単です。またインストールした環境はコンテナなので、失敗しても削除できますしすぐやり直すことができます。気軽にテストすることができます。
今回は Debian で GUI の日本語入力環境を整えてみます。
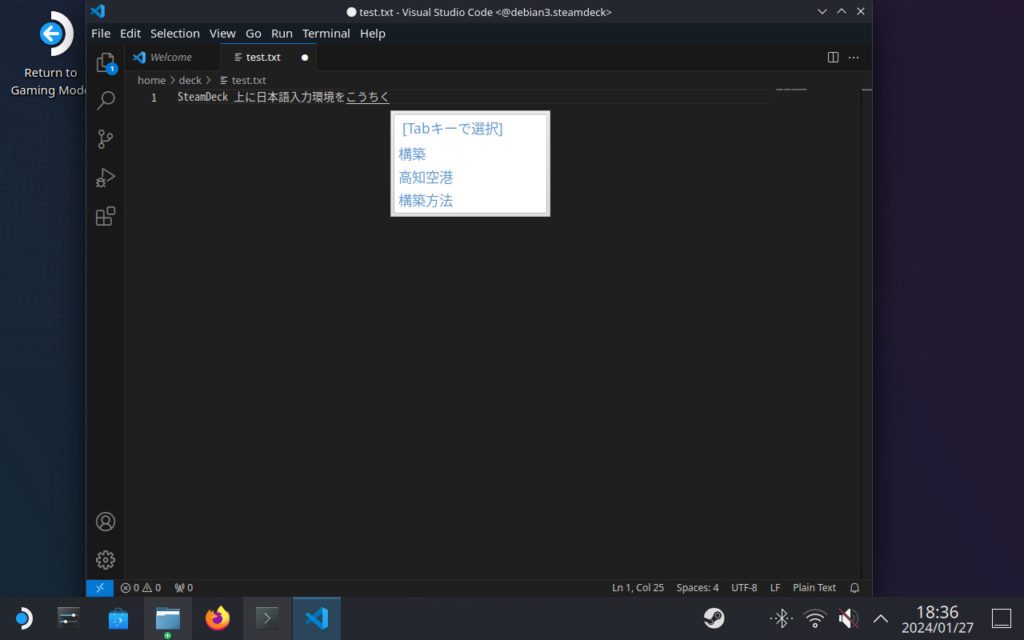
先に USB または Bluetooth キーボードを接続しておいてください。マウスもあった方が良いですが、SteamDeck 右側のタッチパッド + R2(左クリック) / L2(右クリック) でも代用できます。
(1) SteamOS のデスクトップに切り替える
- 「STEAM」ボタン → 「電源」→「デスクトップに切り替え」
以降再起動でゲーミングモードに戻った場合は、再びこの操作でデスクトップに切り替えてください
(2) 日本語表示に切り替える
- デスクトップ左下の Application Launcher アイコン → Settings → System Settings
- Regional Settings → 一番上にある Language 右端の「Modify…」
- 「Change Language」→「日本語」を選択
- 右下の「Apply」→ 右上の「Restart now」→「OK」
- 再起動するので、再びデスクトップに切り替えておきます。
(3) キーボードを日本語配列に切り替える
接続したキーボードが日本語配列の場合以下の設定を行います。英語配列キーボードを使用していて不要な場合はスキップしてください。
- デスクトップ左下の「アプリケーションランチャー」アイコン → 設定 → KDE システム設定
- 入力デバイス →「レイアウト」タブを選択 → 「レイアウトを設定」にチェックを入れる
- 「+Add」ボタン → Search欄に「109」を入れて「日本語 (OADG 109A)」を選択 → OK
- もとからあった英語配列を削除します。”英語(US) ” を選択して「-Remove」ボタンで削除
- 右下の「適用」クリック → 設定ウィンドウを閉じる
(4) ホームディレクトリに .distroboxrc を作成
- デスクトップ左下の「アプリケーションランチャー」アイコンから「ユーティリティ」→「KWrite」を開く
- メニューの「ファイル」→「新規」
- 以下の内容を書き込む
xhost +si:localuser:$USER
export PIPEWIRE_RUNTIME_DIR=/dev/null
- メニューの「ファイル」→「名前をつけて保存」
- 左上の「場所」の中から「ホーム」をクリックして選択
- 下の「名前(N):」の欄に「 .distroboxrc 」と入力
- 右下の「保存(S)」をクリック
- KWrite のウィンドウを閉じる
(5) ホームディレクトリの .bashrc を編集
- 画面左下のアプリケーションランチャーアイコンから「ユーティリティ」→「KWrite」を開く
- メニューの「ファイル」→「開く」
- 下の「名前(N):」の欄に「.bashrc」を入力して右下の「開く」をクリック
- 一番下に以下の内容を入力
export LANG=ja_JP.UTF-8
export DefaultIMModule=fcitx
export GTK_IM_MODULE=fcitx
export QT_IM_MODULE=fcitx
export XMODIFIERS=@im=fcitx
- メニューの「ファイル」→「保存」を選択してから KWrite のウィンドウを閉じる
(6) ターミナルから Debian をインストール
- 画面左下のアプリケーションランチャーアイコンから「システム」→「Konsole」を開く
- ターミナル (Konsole) 内で以下のコマンドを実行
- (“$” はプロンプトを意味するので、$ を除いた空白以降 “distrobox create ~” 部分を入力して Enter を押します。以後同じです)
$ distrobox create -i debian:12 -n debian
- “Do you want to pull the image now? [Y/n]:” と表示されたら「Y] を入力
(7) Debian 環境に入る
- 同じようにコンソールのコマンドラインから以下のように実行します。
$ distrobox enter debian
初回はインストールが入るので時間がかかります。
Debian 環境に入るとプロンプトが「(deck@steamdeck ~)$」から「deck@debian:~$」に変わります。
(8) Debian 上で環境構築
以後同じプロンプト「$」で表現していますが Debian に入った状態で行います。
- 以下のコマンドを実行します
$ sudo apt update $ sudo apt upgrade -y $ sudo apt install -y locales $ sudo dpkg-reconfigure locales
- 言語選択画面になるので、キーボードから [j] キーを入力
- ja_JP.UTF-8 が選択されているので [SPACE] キーを押して選択状態にします (“*” マークが付きます)
- 同時に下段の < OK > が選択されているはずなので、そのまま [Enter] を 2回押して終了します
- 同じようにコンソールから以下のコマンドを実行します
$ sudo apt install -y task-japanese $ sudo apt install -y fonts-noto-cjk $ sudo apt install -y fcitx-mozc $ fcitx
これで Debian 側でインストールしたアプリケーションは日本語入力が可能になります。
(9) キーボード配列の設定その2
タスクバーの右下あたりにキーボードのアイコンが追加されていることを確認します
- タスクバーにあるキーボードのアイコン右クリック→「設定」
- 「入力メソッド」のタブに、以下のように Mozc が並んでいれば OK です
キーボード - 日本語 - 日本語(OADG 109A) Mozc
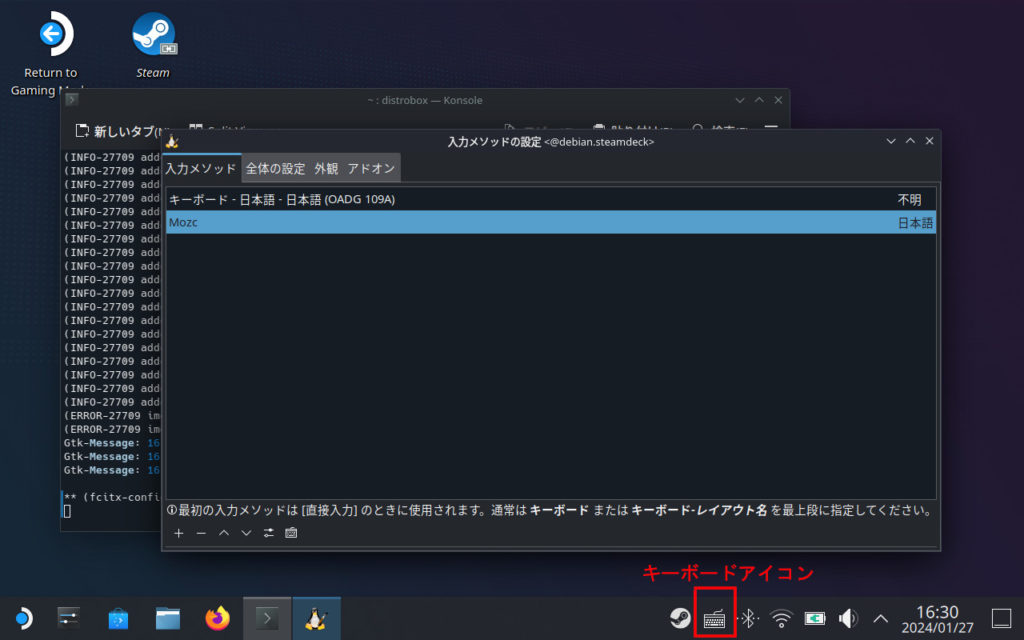
- もし日本語キーボードを使用しているのに、上の段が「キーボード ~ 日本語 (OADG 109)」になってない場合は切り替えてください
- 画面下の「+」ボタンから新たに「日本語」配列を追加して、「-」ボタンで不要なものを削除しておきます
- タブを「全体の設定」に切り替えます
- 入力メソッドのオンオフ」の部分で、日本語入力切り替え方法を確認します
- デフォルトでは「Ctrl+Space」が設定されているはずです。
- 設定ウィンドウを閉じます
これであとは Debian 側でインストールしたアプリケーションは日本語入力ができます。日本語入力への切り替えは「Ctrl」を押しながらスペースキーです。
注意点としては、デスクトップ左下のアプリケーションランチャーからは起動できず、Debian のコマンドラインから起動する必要があります。またこの手順では自動起動のの設定をしていないので、再起動後は手動で fcitx を起動する必要があります。
再起動後やゲームモードから切り替えた場合に再び Debian 環境に入る手順
- Konsole を起動し、ターミナル内で「 distrobox enter debian 」を実行
- Debian 環境に入ったらコマンドラインで「fcitx」を実行
タスクバーにキーボードのアイコンがない場合は手動で fcitx を起動してください。
以下アプリケーションごとのインストール例
あくまで例なので必要に応じてどうぞ。
Firefox
Debian 環境に入った状態で以下のようにインストールします。インストールが終われば firefox コマンドで起動できます。この firefox 上では [Ctrl] + [SPACE] で日本語入力ができます。
$ sudo apt install -y firefox-esr $ firefox
起動時に「KDE ウォレットサービス」の画面が表示された場合はとりあえずキャンセルします。
なお、この Firefox は SteamOS 側のアプリケーションランチャーやタスクバーからは起動できないので注意が必要です。必ず distrobox enter debian で Debian 環境に入ったあとに、コマンドラインから firefox を起動してください。
Chrome
- firefox で Chrome for Linux をダウンロードします。「64bit .deb (Debian/Ubuntu 用)」を選択します
- ダウンロードしたファイルは Downloads フォルダに入っているので、Debian 環境に入ってからコマンドラインで以下のようにインストールします
$ sudo apt install -y $HOME/Downloads/google-chrome-stable_current_amd64.deb $ google-chrome
- インストールが終わったら「google-chrome」コマンドで起動できます
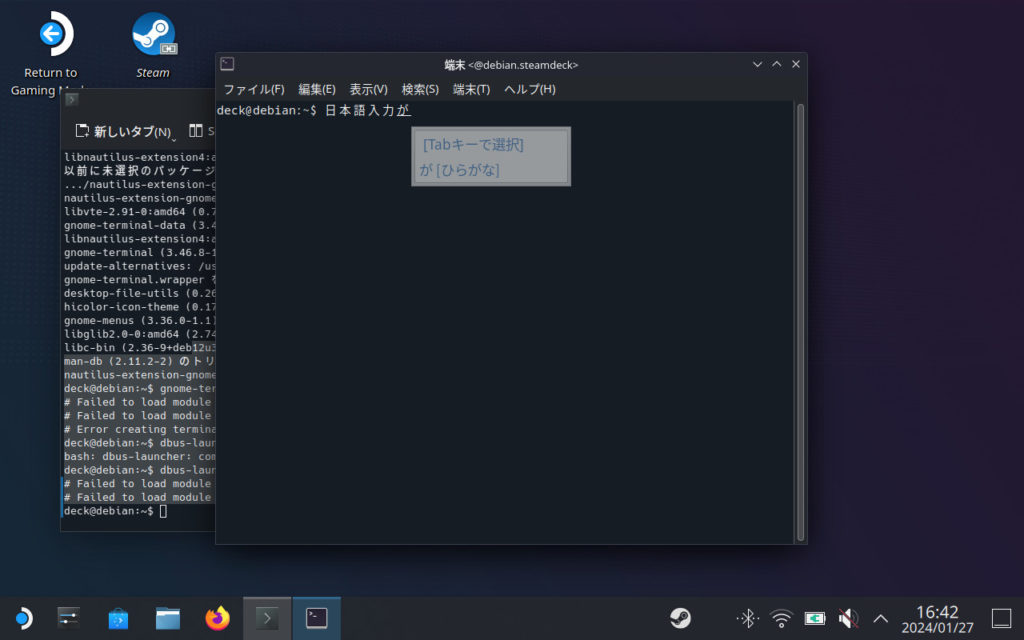
gnome-terminal
- Debian 環境に入ってからインストールします
$ sudo apt install -y gnome-terminal $ dbus-launch gnome-terminal
- ターミナルを起動するには「dbus-launch gnome-terminal」コマンドを実行します
Debian 側から起動したこのターミナルでは日本語入力ができます
VSCode
chrome と同じようにブラウザ上で「~.deb」ファイルをダウンロードし、「apt install 」コマンドでインストールします
- firefox で https://code.visualstudio.com を開いて 「.deb」ボタンから VSCode をダウンロードします
- ダウンロードが完了すると Downloads フォルダに入っているので、apt コマンドでインストールします (バージョンによってファイル名は異なります)
$ sudo apt install -y $HOME/Downloads/code_1.85.2-1705561292_amd64.deb $ code
- インストールが完了したら、code コマンドで起動できます。もちろんテキストエディタとして普通に日本語入力できます。
Distrobox の管理
SteamOS 側のコマンドライン上で管理できます。同時に複数の環境を実行しないよう、不要なものは stop しておいてください。
インストールされているコンテナの確認
$ distrobox list
実行中のコンテナの停止
$ distrobox stop debian
名前をつけて別の Debian 環境を作成
$ distrobox create -i debian:12 -n debian2
その他詳しくは公式サイトをご覧ください。
活用など
SteamDeck の SteamOS はタブレットやスマートフォンのように電源ボタンによるスリープができます。いつの間にか電源が入っていて知らないうちにバッテリーを消費しているなんてこともなく安定しています。バッテリーも TDP を 3W まで下げることができるので、色々使えるのではないかと思ってます。